AI-Powered Processing of 500+ Page Bid Packs at Scale (2/4)
Big organizations drown in documents: 500-plus-page PDFs, scanned annexes, tables, and forms that arrive not once, but all the time. Shoving entire files into an LLM is slow, expensive, and hard to defend. This post shows a better way with AI: extract a small, testable catalog of requirements, index the documents locally, retrieve only the few passages that matter, and demand verbatim, page-linked evidence.
We use procurement as the running example, but the same pattern applies anywhere you process large volumes of pages: vendor risk and security due diligence, contract and policy review, healthcare and regulatory dossiers, M&A data rooms, insurance claims, ESG reports, and more.
Finding the Right Snippets in 500-Page Bid Packs (Without Missing the Good Stuff)
In Part 1 we proved why “just send the whole document” doesn’t scale: it’s slow, expensive, and not audit-friendly. The alternative was to turn the RFP into a rule catalog, index the bidder’s pack locally, and send only a few high-signal snippets per rule. This post zooms into the retrieval step, which is a reliable middle layer that decides which two to four passages we show the model.
Think of retrieval as triage. We’re not judging; we’re picking the sentences and table rows that deserve to be judged. Done well, retrieval keeps tokens low and accuracy high. Done poorly, it either sends fluff (and you pay for it) or misses the one line that matters. Our goal here is a recipe you can implement in a few hours and trust on your first tender.
The shape of a “good” snippet
A good snippet is small, complete, and anchored. Small means ~180-240 tokens (roughly 700–1,000 characters). Complete means a single thought that can be judged in isolation: a bullet item, a legal sentence, or a table row. Anchored means you carried the page number and heading path along for the ride so you can cite it later. The trick is to send two to four such snippets per rule, and to make sure they complement one another rather than repeat themselves.
What makes retrieval work in practice
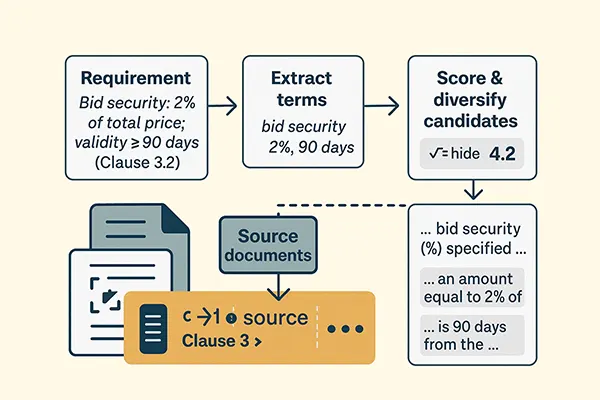
We'll outline the logic first, then show code. We begin with the rule itself, say: “Bid security: 2% of total price; validity ≥ 90 days (Clause 3.2).” Two things jump out: sentry terms and section hints. Sentry terms are the tokens we can’t miss (“2%”, “90 days”, “bid security”, “bond”, “validity”). Section hints are the parts of the document where such things usually live (“Section III > 3.2 Bid Security”, “Annex G > Forms”). When we search, we make sure both get a proper say.
Then we retrieve broadly in two cheap ways: a classical keyword search (BM25) that loves numbers and acronyms, and a one-time tagger that marked chunks with obvious patterns (percentages, money, days, ISO codes, table rows, words like “bond/security/guarantee”). If either method is excited about a chunk, it makes the candidate list. That union step is how we avoid early tunnel vision.
From the candidate list we compute a simple “evidence quality” score: chunks that contain all sentry terms, live near the right section, or are table rows for numeric rules get a boost; long verbose paragraphs get a small penalty. We sort, pick the best one, and then deliberately pick the next from a different page or section or format (table vs narrative). That diversity move does more for recall than any fancy neural reranker in this domain.
Finally, we keep a safety net: if the rule is mandatory and we did not see the key number or unit in any chosen snippet, we widen the search just for this rule (synonyms, tables first, neighboring sections), raise the number of snippets from three to five, and try again. We would rather spend a few hundred extra tokens on a must-catch rule than miss a disqualifier.
Minimal C# data shapes
These are the tiny records we'll use in the examples. They are best kept this way: simple, typed, and small.
public sealed record Requirement(
string Id, // "R12"
string Text, // "Bid security: 2% of total price; validity >= 90 days"
bool Mandatory,
string? ClauseRef // "Section III > 3.2 Bid Security"
);
public sealed record Chunk(
string Id, // "p47_c03"
int Page,
string HeadingPath, // "Section III > 3.2 Bid Security"
string Text,
bool IsTableRow
);
public sealed record Candidate(Chunk Chunk, double Score);
You’ll already have the chunks from Part 1 (180–240 tokens each, ~35% overlap, no splitting of bullets or table rows). We’ll add the indexing and tagging now.
A tiny BM25 index (Lucene.NET)
Lucene.NET gives you battle-tested BM25 right away. Index each chunk with fields for text, page, and heading. When you search, you’ll form a query from the rule’s sentry terms and ask for the top N (e.g. like N = 30 - it’s cheap and wide).
public interface ISearchIndex
{
void Add(Chunk c);
// returns (chunk, rank) with rank starting at 1
IReadOnlyList<(Chunk Chunk, int Rank)> Search(string query, int topN = 30);
}
Implementation notes: store Chunk.Id in a stored field so you can round-trip to your in-memory chunk catalog. Use BM25Similarity (it’s the default in modern Lucene). Keep tokenization simple; here numbers and acronyms matter.
One-time “obvious” tags
This is your cheap second net. We run it once per chunk, store the tags alongside, and never pay for it again. It’s not fancy, but it is very useful. You include numbers, percentages, days, ISO/EN codes, “bond/security/guarantee,” “shall/must,” and whether it’s a table row.
public static class Tags
{
public static readonly Regex Money = new(@"(?i)(€|\$|USD|EUR|GBP|)\s?\d[\d\.\, ]*", RegexOptions.Compiled);
public static readonly Regex Percent = new(@"(?<!\d)(\d{1,3})\s?%", RegexOptions.Compiled);
public static readonly Regex Days = new(@"(?i)\b\d{1,4}\s+(calendar|working)?\s*days?\b", RegexOptions.Compiled);
public static readonly Regex Bond = new(@"(?i)\b(bid|performance)\s+(bond|security|guarantee)\b", RegexOptions.Compiled);
public static readonly Regex Iso = new(@"(?i)\bISO\s?\d{3,5}(:\d{4})?\b|\bEN\s?\d+\b", RegexOptions.Compiled);
public static readonly Regex Must = new(@"(?i)\b(shall|must|required|grounds for rejection)\b", RegexOptions.Compiled);
}
public static HashSet<string> TagChunk(Chunk c)
{
var t = new HashSet<string>();
if (Tags.Money.IsMatch(c.Text)) t.Add("money");
if (Tags.Percent.IsMatch(c.Text)) t.Add("percent");
if (Tags.Days.IsMatch(c.Text)) t.Add("days");
if (Tags.Bond.IsMatch(c.Text)) t.Add("bond");
if (Tags.Iso.IsMatch(c.Text)) t.Add("iso");
if (Tags.Must.IsMatch(c.Text)) t.Add("must");
if (c.IsTableRow) t.Add("table");
return t;
}
Persist the tag set per chunk. Later, when a rule mentions a bond or a percentage, you can union BM25 results with all chunks pre-tagged bond or percent.
From rule text to a “wide” query
We don’t want the perfect query; we want a generous one. Pull numbers and units, canonicalize a few variants, and add light synonyms. Keep it deterministic and fast.
public sealed record QueryTerms(
IReadOnlyList<string> MustHave, // e.g. ["bid", "security"] or ["bond"]
IReadOnlyList<string> Numbers, // e.g. ["2%","90 days"]
IReadOnlyList<string> Synonyms // e.g. ["guarantee"]
);
public static QueryTerms ExtractTerms(Requirement r)
{
var must = new List<string>();
var nums = new List<string>();
var syns = new List<string>();
var text = r.Text.ToLowerInvariant();
if (text.Contains("bid security") || text.Contains("bond"))
must.AddRange(new[]{"bid","security"});
if (text.Contains("validity")) must.Add("validity");
if (text.Contains("percent") || text.Contains("%")) nums.Add("2%"); // parse actual number
if (text.Contains("days")) nums.Add("90 days"); // parse actual number
if (text.Contains("bond")) syns.AddRange(new[]{"guarantee","security"});
return new QueryTerms(must, nums, syns);
}
public static string BuildQuery(QueryTerms q)
{
// naive bag-of-words; for Lucene you’d craft a BooleanQuery
var all = q.MustHave.Concat(q.Numbers).Concat(q.Synonyms);
return string.Join(" ", all.Distinct());
}
In your real code, actually parse the numbers (“two percent” vs “2%”), but keep it simple: exact digits beat clever NLP here. Make it work first, then later keep improving it in iterations.
Fusing BM25 hits with tagged candidates
This is the point where we avoid missing evidence: anything that either search or tags like will be considered. We usually use reciprocal rank fusion (RRF) because it's two lines and surprisingly robust: give a candidate , with a constant around 60 to dampen outliers.
public static IReadOnlyList<Chunk> Fuse(
IReadOnlyList<(Chunk Chunk, int Rank)> bm25,
IEnumerable<Chunk> tagged,
int k = 60)
{
var scores = new Dictionary<string,double>();
// BM25 contributes 1/(k+rank)
foreach (var (chunk, rank) in bm25)
scores[chunk.Id] = scores.GetValueOrDefault(chunk.Id) + 1.0 / (k + rank);
// Tagged chunks contribute as if they were near the top (rank ~ 10)
int pseudoRank = 10;
foreach (var c in tagged)
scores[c.Id] = scores.GetValueOrDefault(c.Id) + 1.0 / (k + pseudoRank);
return bm25.Select(x => x.Chunk).Concat(tagged)
.DistinctBy(c => c.Id)
.OrderByDescending(c => scores.GetValueOrDefault(c.Id))
.ToList();
}
If you want tagged candidates to be weaker, increase pseudoRank to 20-30; if stronger, drop it to 5-10.
Scoring “evidence quality”
Here’s where we prefer chunks that actually help the model: containing the numbers we care about, living in the right section, being table rows for numeric rules, and not being overly long. This is a plain, explainable linear function. You’ll tune weights in an hour by eyeballing a few tenders.
public static double Score(Requirement r, QueryTerms q, Chunk c)
{
double s = 0.0;
// 1) raw term coverage
foreach (var t in q.MustHave)
if (c.Text.Contains(t, StringComparison.OrdinalIgnoreCase)) s += 1.0;
foreach (var n in q.Numbers)
if (c.Text.Contains(n, StringComparison.OrdinalIgnoreCase)) s += 2.0; // numbers matter
// 2) section hint
if (!string.IsNullOrWhiteSpace(r.ClauseRef) &&
c.HeadingPath.Contains(r.ClauseRef, StringComparison.OrdinalIgnoreCase))
s += 1.5;
// 3) tables are gold for numeric rules
if (c.IsTableRow && (q.Numbers.Count > 0))
s += 1.0;
// 4) length penalty (prefer ~200-token chunks)
var len = c.Text.Length;
if (len > 1200) s -= 0.5; // too long
if (len < 400) s -= 0.2; // sometimes too short to stand alone
return s;
}
You don’t need perfection here; you need a stable bias toward chunks that carry digits and live near the right heading. That bias lets you keep most of the time.
Forcing diversity
After you sort by score, don’t just take the top three. Take the first one, then deliberately choose the next from a different page or a different heading, or a different format (table vs paragraph). This is a quick but a somewhat inferior fix for Maximal Marginal Relevance (MMR) and it pays off immediately.
public static bool IsDiverse(Chunk next, IReadOnlyList<Chunk> chosen)
{
// prefer different page or different heading or different format
foreach (var c in chosen)
{
bool samePage = c.Page == next.Page;
bool sameHeading = string.Equals(c.HeadingPath, next.HeadingPath, StringComparison.OrdinalIgnoreCase);
bool sameForm = c.IsTableRow == next.IsTableRow;
// If everything is the same, it's not diverse
if (samePage && sameHeading && sameForm) return false;
}
return true;
}
In practice this produces a good mix: one narrative sentence near the clause, one table row from Annex G, and maybe one paragraph where the bank guarantee language lives, or something similar.
Putting it together: SelectPassages
This is the glue that runs the pipeline for one rule: extract terms, search, pull tagged candidates, fuse, score, and pick diverse top-k. If the rule is mandatory and we didn’t catch the numbers, we escalate.
public IEnumerable<Chunk> SelectPassages(
Requirement rule,
ISearchIndex index,
IReadOnlyList<Chunk> allChunks,
Func<Chunk, HashSet<string>> tagProvider,
int k = 3)
{
var terms = ExtractTerms(rule);
var query = BuildQuery(terms);
var bm25 = index.Search(query, topN: 30);
var tagged = allChunks.Where(c => ShouldConsiderByTag(rule, tagProvider(c)));
var fused = Fuse(bm25, tagged);
var scored = fused
.Select(c => new Candidate(c, Score(rule, terms, c)))
.OrderByDescending(x => x.Score)
.ToList();
var chosen = new List<Chunk>();
foreach (var cand in scored)
{
if (chosen.Count == 0) { chosen.Add(cand.Chunk); continue; }
if (IsDiverse(cand.Chunk, chosen)) chosen.Add(cand.Chunk);
if (chosen.Count >= k) break;
}
// Safety net: if mandatory and no numbers show up, widen search
if (rule.Mandatory && terms.Numbers.Count > 0 &&
!chosen.Any(c => terms.Numbers.Any(n => c.Text.Contains(n, StringComparison.OrdinalIgnoreCase))))
{
var widened = WidenSearch(rule, index, allChunks, tagProvider);
foreach (var w in widened)
{
if (IsDiverse(w, chosen)) chosen.Add(w);
if (chosen.Count >= Math.Max(k, 5)) break;
}
}
return chosen;
}
private static bool ShouldConsiderByTag(Requirement r, HashSet<string> tags)
{
var t = r.Text.ToLowerInvariant();
if (t.Contains("bond") || t.Contains("security") || t.Contains("guarantee"))
return tags.Contains("bond") || tags.Contains("percent") || tags.Contains("money");
if (t.Contains("iso") || t.Contains("en"))
return tags.Contains("iso");
if (t.Contains("price") || t.Contains("unit") || t.Contains("incoterms"))
return tags.Contains("table") || tags.Contains("money");
if (t.Contains("days") || t.Contains("validity"))
return tags.Contains("days");
return tags.Contains("must"); // default bias to compulsory-ish language
}
WidenSearch can be as simple as trying synonyms (“two percent” vs “2%”), expanding the section window (neighbor headings), or prioritizing IsTableRow. Keep it constrained to this rule only; we’re spending tokens where it matters.
A quick example end-to-end
Say the rule is R12 (bid security 2% and 90 days). The BM25 search surfaces three paragraphs near Section 3.2 and one in a general conditions section. The tagger surfaces two table rows in Annex G with “Bank Guarantee … amount: 2% … validity: 90 days.” Fuse and score put a clause paragraph first, a table row second, and another paragraph third. The diversity filter picks one from Section 3.2 (page 47) and one from Annex G (page 112). The third is on page 48, so we skip it to avoid near-dupes and instead grab a row from page 113. We send these three to the model. If for some reason none contains “90 days”, the safety net widens to include page 49 where “ninety (90) days” appears.
This is the proper way of doing it by not overthinking it: you just give the model three pieces of text that a human would also read.
Let us show you a sample catalog with rules, as it’s easier to visualize the process with a concrete example:
public static class DemoCatalog
{
public static readonly List<Requirement> Requirements = new()
{
// Administrative (Admin)
new("R12", "Admin", true, "Bid security: 2% of total price; validity >= 90 days.", "Section III > 3.2 Bid Security"),
new("R14", "Admin", true, "Bid validity >= 120 calendar days.", "Section III > 3.4 Bid Validity"),
new("R21", "Admin", true, "ISO 9001:2015 and ISO/IEC 27001:2013 certificates are current.", "Administrative > Certifications"),
new("A01", "Admin", true, "Form BS-1 (Bid Security) is completed and signed.", "Annex G > Forms > BS-1"),
new("A02", "Admin", true, "Power of Attorney for signatory is included and valid on submission date.", "Administrative > Powers of Attorney"),
new("A03", "Admin", true, "Insurance: General Liability coverage evidence provided.", "Administrative > Insurance Certificates"),
new("A04", "Admin", false, "Conflict of Interest declaration signed.", "Administrative > Declarations"),
new("A05", "Admin", true, "All required forms are present: BS-1, PV-2, EC-4.", "Section III > 3.9 Grounds for Rejection"),
// Technical (Technical)
new("T05", "Technical", true, "Meters meet IEC 62053-21 Class 1 and 62053-22 Class 0.5S.", "Technical > Meter Performance"),
new("T06", "Technical", true, "Independent test reports provided for stated meter classes.", "Annex T > Test Reports"),
new("T07", "Technical", false, "Head-End System supports DLMS/COSEM (IEC 62056 series).", "Technical > Communications"),
new("T08", "Technical", false, "Firmware upgrade process documented with rollback procedure.", "Technical > Lifecycle & Updates"),
new("T09", "Technical", false, "Device tamper detection features described and verified.", "Technical > Meter Security Features"),
new("T10", "Technical", false, "Localization: UI and manuals available in required languages.", "Technical > Documentation"),
// Security (Security/InfoSec)
new("S01", "Security", true, "ISMS aligned to ISO/IEC 27001 with current Certificate and SoA.", "Security > ISO 27001"),
new("S02", "Security", false, "SOC 2 Type II report (or equivalent) provided for HES/Cloud components.", "Security > SOC Reports"),
new("S03", "Security", true, "Security controls mapped to NIST CSF categories ID, PR, DE.", "Technical > Communications > Security"),
new("S04", "Security", false, "Data residency and backup/restore RTO/RPO documented.", "Security > BC/DR"),
new("S05", "Security", false, "DPA/Data Processing Agreement signed, with subprocessor list.", "Legal > Data Protection"),
// Service Levels (Service)
new("SV1", "Service", true, "Defective meters replaced within 5 working days of notification.", "Section VII > 7.3 Replacement and Repair"),
new("SV2", "Service", false, "Support desk hours and response times meet SLA targets.", "Service Levels > Support & Response"),
new("SV3", "Service", false, "Preventive maintenance plan and schedule provided.", "Service Levels > Maintenance"),
// Commercial (Commercial)
new("C08", "Commercial",false, "LDs: 0.1% per day capped at 10% accepted.", "Commercial > Terms"),
new("C09", "Commercial",true, "Price Schedule PV-2 completed with line item totals and delivery days.", "Annex G > Forms > PV-2"),
new("C10", "Commercial",false, "Incoterms and delivery responsibilities clearly stated.", "Commercial > Delivery Terms"),
new("C11", "Commercial",false, "Warranty terms specified: duration and coverage scope.", "Commercial > Warranty"),
// Delivery & Project (Delivery)
new("D01", "Delivery", false, "Master delivery plan with milestones and lead times provided.", "Project > Delivery Plan"),
new("D02", "Delivery", false, "Resource plan detailing installation teams and qualifications.", "Project > Resourcing"),
// HSE / QA (HSE)
new("H01", "HSE", false, "HSE plan aligned with local regulations and employer policy.", "HSE > Plan"),
new("H02", "HSE", false, "Quality plan covers inspection, calibration, and nonconformity handling.", "Quality > Plan"),
// Legal (Legal)
new("L01", "Legal", true, "All deviations/exceptions to contract terms are listed in the deviation table.", "Legal > Deviations"),
new("L02", "Legal", false, "Parent company guarantee provided if bidder is a consortium/SPV.", "Legal > Guarantees")
};
// Convenience: lookup by Id
public static Requirement? Get(string id) => Requirements.FirstOrDefault(r => r.Id == id);
}
What you send to the model (and what you don’t)
This is a retrieval post, not a prompting post, but it’s worth restating: you send only the rule text and the two to four snippets we just selected, with page numbers and headings attached. You do not send the whole document, and you do not ask the model to search. Your instruction is a small must-cite contract: output JSON with a status, a short rationale, a verbatim quote from one of the passages, and the page numbers. If it cannot quote, it must return “Missing”. When the JSON comes back, you verify the quote locally with a plain string match. That one rule keeps the model honest and your audit trail clean.
Using the catalog shown in the previous section, let's take five rules and show how the example payload would look like:
{
"instructions": "You are a compliance checker. For each item, read the requirement and only the provided passages. Return strict JSON with fields: status = {Pass,Partial,Fail,Missing}, rationale (< 80 words), evidence_quote (< 40 words) copied verbatim from a passage, page_refs (integers), risk_level = {Low,Medium,High}. If no passage supports compliance, return Missing. Do not infer beyond provided text.",
"items": [
{
"requirement": {
"id": "R12",
"text": "Bid security: 2% of total price; validity >= 90 days.",
"mandatory": true
},
"passages": [
{
"page": 47,
"heading": "Section III > 3.2 Bid Security",
"text": "The bid security shall be two percent (2%) of the total bid price and shall remain valid for at least ninety (90) days after bid validity expires."
},
{
"page": 112,
"heading": "Annex G > Forms",
"text": "Form BS-1: Bank Guarantee … amount: 2% of total price; validity: 90 days …"
},
{
"page": 113,
"heading": "Annex G > Forms",
"text": "Form BS-1 (alt template): Bank Guarantee - Amount: two percent (2%); Validity: ninety (90) days."
}
]
},
{
"requirement": {
"id": "R14",
"text": "Bid validity >= 120 calendar days.",
"mandatory": true
},
"passages": [
{
"page": 52,
"heading": "Section III > 3.4 Bid Validity",
"text": "Bids shall remain valid for one hundred twenty (120) calendar days from the bid submission deadline."
}
]
},
{
"requirement": {
"id": "R21",
"text": "ISO 9001:2015 and ISO/IEC 27001:2013 certificates current.",
"mandatory": true
},
"passages": [
{
"page": 65,
"heading": "Administrative > Certifications",
"text": "ISO 9001:2015 Certificate No. Q-912345, valid to Dec 31, 2026. ISO/IEC 27001:2013 Certificate No. IS-778899, valid to Nov 15, 2026."
}
]
},
{
"requirement": {
"id": "T05",
"text": "Meters meet IEC 62053-21 Class 1 and 62053-22 Class 0.5S.",
"mandatory": true
},
"passages": [
{
"page": 171,
"heading": "Technical > Meter Performance",
"text": "Single-phase meters tested to IEC 62053-21 Class 1. Three-phase meters to IEC 62053-22 Class 0.5S."
}
]
},
{
"requirement": {
"id": "C08",
"text": "LDs: 0.1%/day capped at 10% accepted.",
"mandatory": false
},
"passages": [
{
"page": 417,
"heading": "Commercial > Terms",
"text": "We accept LDs of 0.1% of monthly invoice per day, capped at 10% of the monthly invoice."
}
]
}
]
}
Real-life challenges
There are some challenges with a real-life code when you do this processing, and it is worth mentioning it.
If you see too many near-duplicates, tighten the diversity rule to prefer different pages first, then different headings, then different formats. If you miss numbers, raise the numeric term weight in Score or guarantee at least one table row when Numbers.Count > 0. If your BM25 index loves the wrong section, add a bigger bonus when HeadingPath contains ClauseRef. If your tagger drags in junk, raise pseudoRank in the fusion score so tags help but don’t dominate.
Every one of these tunings is simple and visible, which is the whole point. You don’t need a research team; you need an afternoon and a few real documents.
Where we go next
Now that retrieval is in place, we can talk about the other bottleneck people hit in the real world: rate limits. Azure and peers cap both requests per minute and tokens per minute. In Part 3 we'll show how to keep the same accuracy while slashing latency: pack multiple rules in a single call, run a quick triage pass before a full pass, and do just enough scheduling to stay well inside the limits. We’ll do the token math again so you can predict costs before you hit “analyze.”
It is important to note: retrieval isn’t magical, it’s mechanical. Search wide, favor evidence, force variety, and keep a safety net for mandatory rules. Do that, and you’ll never again feel the urge to dump 500 pages into a prompt and hope for the best.
Discussion Board Coming Soon
We're building a discussion board where you can share your thoughts and connect with other readers. Stay tuned!
Ready for CTO-level Leadership Without a Full-time Hire?
Let's discuss how Fractional CTO support can align your technology, roadmap, and team with the business, unblock delivery, and give you a clear path for the next 12 to 18 months.
Or reach us at: info@sharplogica.com